

Genetics research has made momentous strides in the 21st century. At the start of the century, we had a broad understanding that most medical problems in the developed world are partly genetically determined but lacked the technology to fully explore the secrets hiding in our genome.
This century’s technological advances have allowed us to make substantial progress in identifying the genomic underpinnings of heart disease, mental health disorders, cancer, dementia, and other diverse diseases that medicine still struggles to prevent, diagnose and treat.
We can now quantify the overall genetic contribution (heritability) and identify specific genetic variants that contribute to the risk of these diseases. But, as with most things genetic, it’s complex, it’s incomplete and scientists are still working out how to make it clinically useful.
Each of these diseases and disorders has a “polygenic” underpinning. This means that instead of only one or a few genes playing a role in the risk of diseases, it is likely to be thousands of genes where inherited changes in each gene make a modest impact on our risk of each disease. This dispersed genetic component combines with other environmental risk factors – such as smoking, diet, trauma and stress – to further increase or decrease our risk of ill health.
This polygenic underpinning is good news in many ways: our risk is determined by multiple genetic variants and usually not by a single yes/no genetic risk factor. Some single genetic risk factors do exist, such as variants in the BRCA1 and BRCA2 genes that substantially increase the risk of breast and ovarian cancer. But these single-hit genetic variants are rare – meaning that, for most of us, genetic predisposition comes from the combined risk of many variants.
Genetic studies over the past 20 years have identified many such variants that contribute to the polygenic loading for disease: more than 100 for breast cancer, depression and coronary artery disease, and 38 for Alzheimer’s disease. All these variants can give us information on the underlying biology and new targets for drug development. These variants can also contribute to the calculation of risk scores, indicating those who are at genetically high risk of disease and those who are at low risk.
The term “score” is appropriate here because it can be calculated by simply adding up the number of high-risk genetic variants carried across the genome, weighted by the importance of each variant.
If you look at polygenic scores for a large group of people, most people will have a score that is near average, so their genetics adds little information to their disease risk. A few people will have a high polygenic score, putting them at increased risk of developing a particular disease. Others will have inherited few risk variants, putting them at lower risk of disease.
So are polygenic scores useful? Potentially, yes, but mostly no – not yet. Polygenic scores can give us a personal estimate of our genetic risk for a certain disease, which remains constant throughout life and can be calculated at any point. They could give an impetus to lead a healthy lifestyle, undertake appropriate screening, or be watchful for early symptoms.
Polygenic scores are not available through the NHS but can be derived from the genetic data generated by direct-to-consumer genetic testing companies, such as 23andMe, and ancestry companies, such as AncestryDNA. These companies test your DNA from a mailed-in saliva sample and give you the option to download your genetic data to your desktop.
23andMe shows you information on your polygenic risk of type 2 diabetes. And websites such as impute.me allow you to upload your own genetic data to calculate your polygenic scores.
Making sense of your score
The MyGeneRank app gives you your coronary artery disease score on your phone by linking to your 23andMe genetic data. This sounds wonderfully accessible, but what can your coronary artery disease polygenic score actually tell you? First, it can tell where your risk lies compared with other people of the same genetic ancestry as you. For example, if MyGeneRank tells a person that their polygenic score lies at the 55th percentile of the distribution, then their risk lies very close to average.
What about someone who is at the 95th percentile, in the top 5% of people with the highest genetic risk? That might be worrying information, but to interpret a polygenic score you need two further pieces of information. First, you need a “relative risk”: how much does your polygenic score change your risk compared with an average person? Does it double your risk or increase it tenfold? Second, you need a “lifetime risk”: what is your chance of being diagnosed with the disorder?
These figures depend on your genetics, how many people develop the disease and how much of the disease risk the polygenic score explains, which is small for most diseases. For example, a woman with a breast cancer polygenic score in the top 1% of the population has a lifetime risk of about 30%. For most disorders, lifetime risks are lower.
A high polygenic score for schizophrenia might be worrying news for people, but our genetic knowledge of schizophrenia is far from complete. The estimated chance of developing schizophrenia for someone with a high polygenic score, seen only in one in 100 people, is 4% compared with a 1% risk for most of the population. This result may be reassuring, but also shows that schizophrenia polygenic scores should not be used clinically. We have developed an online tool to calculate how the lifetime risk of disease changes at different levels of polygenic scores.
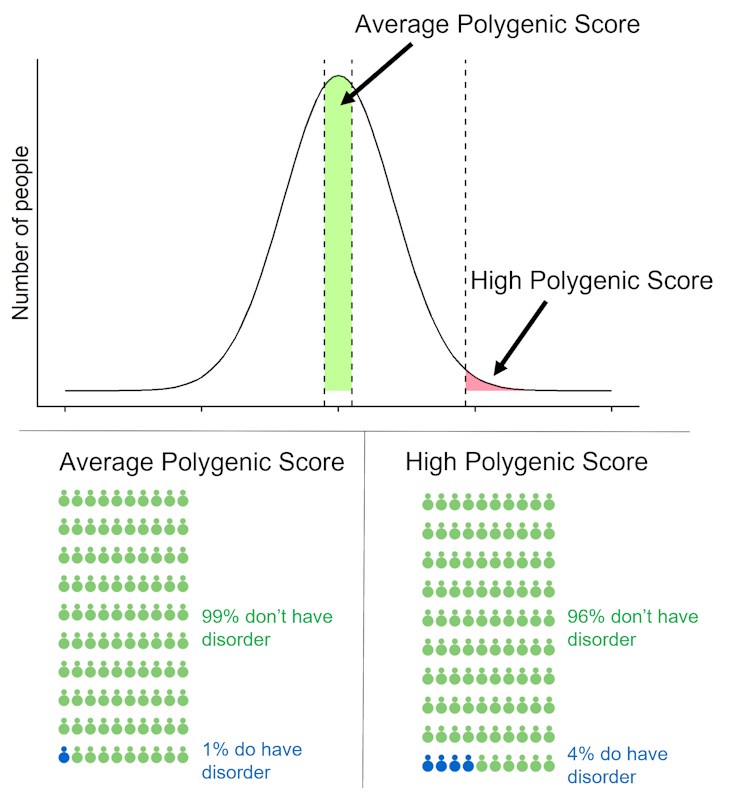 Risk of developing schizophrenia when polygenic score is average or high (top 1%)
Risk of developing schizophrenia when polygenic score is average or high (top 1%)
Polygenic scores give you a snapshot of your genetic risks, but for most disorders, the partial information captured is not strong enough for it to be useful. The next decade will determine whether polygenic scores remain a personal curiosity, or whether they become an important medical tool.![]()
Cathryn Lewis, Professor of Genetic Epidemiology & Statistics, King’s College London and Oliver Pain, Postdoctoral Research Associate, King’s College London
This article is republished from The Conversation under a Creative Commons license. Read the original article.
![]()
![]()


